
New generations of spacecrafts are required to perform tasks with an increased level of autonomy — space exploration, Earth Observation (EO), space robotics, and so on, are all growing fields in the space segments that require more sensors and computational power to perform these missions.
Sensors, embedded processors and hardware, in general, have hugely evolved in the last decade, equipping embedded systems with large number of sensors that will produce data at rates that have not been seen before, while simultaneously having computing power capable of large data processing on-board. Near-future spacecrafts will be equipped with large number of sensors that will produce data at high-speed rates in space and data processing power will be significantly increased.
 Figure 1. AI main components
Figure 1. AI main components
Future missions, such as Active Debris Removal, will rely on novel, high-performance avionics to support image processing and Artificial Intelligence (AI) algorithms with large workloads. Similar requirements come from EO applications, where data processing on- board can be critical in order to provide real-time reliable information to Earth.

This new scenario has brought new challenges with it: low determinism, excessive power needs, data losses and large response latency. In this project, Klepsydra AI is used as a novel approach to on-board artificial intelligence and provides a sophisticated threading model combination of pipeline and parallelization techniques applied to deep neural networks — this makes AI applications far more efficient and reliable.
This new approach has been validated with several Deep Neural Network (DNN) models and two different computer architectures. The results show that the data processing rate and power saving of the applications increase substantially with respect to standard AI solutions.
On-board AI for Earth Observation
The amount of data produced by a multi-spectral camera prevents real-time data transfer to the ground due to the limitations of downlink speeds, thus requiring large, on-board, data storage. Several high-level solutions have been proposed to improve this situation, including the use of on-board AI to filter irrelevant or low-quality data and deliver only a subset of data.
Space Autonomy
In a different field, vision-based navigation, there is also a challenge of data processing combined with AI algorithms. One example is rendezvous with uncooperative objects in space, e.g., debris removal. Another example of this is autonomous pinpoint planetary landing (klepsydra.com/klepsydra-ai-online-demo/), where the number of sensors and the complexity of the Guidance Navigation and Control algorithms make this discipline still one of the biggest challenges in space.
One common element to these two use cases is a well-known fact in control engineering: for optimal control algorithms, the higher the rate of sensor data, the better is the performance of the algorithm. Moreover, communication limitations may result in severe delays in the generation of alarms raised upon detection of critical events.
With Klepsydra, data can be analyzed onboard, in real time, and alerts can be immediately communicated to the ground segment.
Interference In Artificial Intelligence
There are several components to AI. First, there is the training and design of the model. This activity is usually carried out by data scientists for a specific field of interest. Once the model is designed and trained, it can be deployed to the target computer for real-time execution. This is what is called inference and consists of two parts: the trained model and the AI inference engine to execute the model. The focus of this research has been solely on the inference engine software implementation.
Trends in Artificial Intelligence inference acceleration
The most common operation in AI inference, by far, is matrix multiplications. These operations are constantly repeated for each input data to the AI model. In recent years, there has been a substantial development in this area with industry and academia progressing steadily in this field.
While the current trend is to focus on hardware acceleration such as Graphic Processing Units (GPU) and Field-programmable Gate Array (FPGA), these techniques are currently not broadly available to the space industry due to radiation issues and excessive energy consumption for the former, and programming costs for the latter.
The use of CPU for inference, however, has been also undergoing an important evolution, taking advantage of modern Floating Processing Unit (FPU) connected to the CPU. CPUs are widely used in space due to large space heritage and also ease of programming. Several AI inferences engines are available for CPU+FPU setups.
The results of extensive research in building a new AI inference reveals that both reduce power consumption and also increases the data throughput.
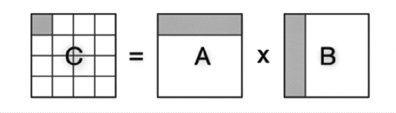
Figure 2. parallel matrix multiplication
Parallel processing applied to AI inference
Within the field of inference engines for CPU+FPU, the focus for performance optimization has been on matrix multiplication parallelization. This process consists in splitting the operations required for a matrix multiplication into smaller to be executed by several threads in parallel. Figure 2 shows an example of this type of process, where rows from the left-hand matrix and columns from the right-hand matrix are individual operations to be executed by different threads.
Data Pipelining
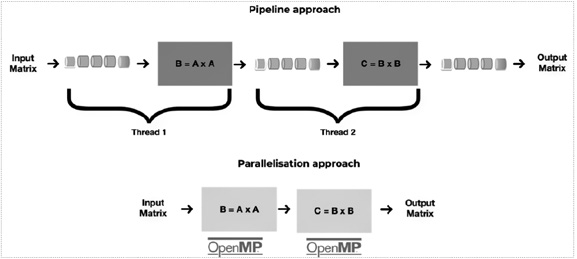
Figure 3. Pipelining vs. parallelization
The theoretical advantage of the above approach is its minimal latency. However, there is an emerging alternative approach to parallelization that is based in the concept of pipelines. This approach works in a similar manner to an assembly line, where each part of this line corresponds to a complete matrix multiplication. This approach is particularly well suited for AI DNN. The main advantage is its higher throughput, as it makes pipeline a reliable approach to data processing in resources constraint environment, like Space on-board computers. Pipelining can enable a substantial increase in throughput with respect to traditional parallelization.
The Threading Model
This new pipelining algorithm consists of these main elements:
• Use of lock-free ring-buffers to connect the matrix multiplications operations.
• Use of FPU vectorization to accelerate the matrix multiplications.
• One ring-buffer per thread, meaning that each matrix multiplication happens in one thread.
 Figure 4.Pipelining approach
Figure 4.Pipelining approach
Combining the concept of pipelining above with lock-free algorithms, a new pipelining approach has been developed. This can process data at 2 to 8 times increased data rate, while at the same time reduce power consumption as much as 75%
The KATESU Project
The current commercial version of Klepsydra AI has been successfully validated in an European Space Agency (ESA) activity called KATESU for Teledyne e2v’s LS1046 and Xilinx ZedBoard onboard computers, with outstanding performance results. As part of this activity, two DNN algorithms provided by ESA were tested: CME1 and OBPMark2
References

1Coronal Mass Ejections
indico.esa.int/event/393/timetable/#25-methods-and-deployment-of-m
2 zenodo.org/record/5638577
David Steenari, Leonidas Kosmidis, Ivan Rodriguez-Ferrandez, Alvaro Jover-Alvarez, & Kyra Förster. OBPMark — (On-Board Processing Benchmarks) – Open Source Computational Performance Benchmarks for Space Applications.— OBDP2021 - 2nd European Workshop on On-Board Data Processing (OBDP2021).— doi.org/10.5281/zenodo.5638577i
Further References
obpmark.org
obpmark.github.io/